Courtesy of Lindybeige:
Llyod is pretty much always great, and this is no exception, despite being a YouTube short.

Courtesy of Lindybeige:
Llyod is pretty much always great, and this is no exception, despite being a YouTube short.
In which I discuss that referring to myself as a sinner is simply true and not rhetorical, as well as draw some lessons to when others (such as Bishop Barron) refer to themselves as sinners and how that should be taken seriously (but without speculating as to the specifics).
The title of the video is a reference to one of my favorite prayers, the Jesus prayer, “Lord Jesus Christ, Son of God, have mercy on me, a sinner.” (This prayer is, itself, a reference to the publican in the story of the pharisee and the publican.)
As Abraham Lincoln once said, the problem with internet quotations is that many of them are not genuine.
Sun Tzu, The Art of War
A while back I looked into a paper that described the actual mathematics/programming behind chatGPT (really, behind GPT3, which is basically the same thing but with a less sophisticated front-end). I find it interesting how often the thing is misunderstood.
ChatGPT is, as it will candidly tell you, a Large Language Model. That language part is very important. It does not model facts, or concepts; it has no understanding of anything. It does not try to have an understanding of anything. What it does is model language, but not in the way that grammarians model language. It models how language is used in practice. That is, it is a model of the sort of things that people actually say.
Without getting into the details of how the model works, it is enough to know that it was trained by taking in the appearance and order of words within approximately everything that the people at openAI were able to scrape off of the internet about two years before going public with chatGPT.
(This, btw, is the big improvement in chatGPT over previous large language models; the T stands for “transformer” and is a particular kind of use of matrices which allows the model to be “trained” in parallel, which allows for massively larger training sets than had previously been used in large language models. That said, its interesting to note that you can’t increase the training size to much larger than “approximately all of the text that has ever been written”, so on this basis alone we’d expect to see improvements in large language models slowing down after chatGPT because improved training is no longer an option. By contrast, this is not a problem for image-generating AI training. Generating massively larger numbers of images is quite straight forward.)
The output of chatGPT can loosely but accurately be described as “the words that the people who wrote the text chatGPT was trained on would probably say following whatever you said to it.” It doesn’t understand subjects and has no concept of what it is saying or the truth or falsity of what it is saying, it only has a concept of the probability of words appearing in an order on the basis of what words came earlier.
Like all modern “AI” stuff, the “AI” part takes input and produces output that a human being would not recognize as related to what the AI is being used for. Translating from a use case into the input of the AI model, and translating from its output back to the use case, is the work of programs written in normal programming languages that the programmers understand quite well. This front-end software is responsible for things like chatGPT being able to use references to previous subjects, or handle special cases like refusing to tell people how to commit crimes or adding a disclaimer to everything it says that is fitness-related that you should consult a doctor. They seem to be constantly adding more to this front-end, such as the ability to take instructions like, “write a sentence that ends in the word apple.” A language model only produces a set of words in order that are probable based on its training set; following directions is not related to this. Thus any amount of following directions is entirely in the front-end and consists of programmers looking at what kinds of instructions it’s been given and writing front-end code to handle those cases.
I’ve heard people say things like, “if they add the ability for it to check whether the things it is saying are true,” but no one has developed an AI which can identify what parts of a sentence constitute facts that could be checked. Consider a simple sentence like, “Mary, Queen of Scotts, once placed a bet on a game of tennis.”
What even are the facts that the sentence asserts? Let’s list them:
Some of these facts do imply others. For example: if Mary did in fact bet on a game of tennis, then it must be the case that a game of tennis was played during Mary’s lifetime. That is not necessarily the order you want to check them, though; it is common when fact checking to start with the easy-to-check facts.
There are complications, though. When we say “tennis” do we mean the medieval game played in an indoor court in which the walls (and some roofs) were in play, or do we mean “lawn tennis” which is the modern use of “tennis.” Is the sentence asserting something about Mary relating to the modern game of tennis, or only to the game which was more popularly played in her day and from which the modern game called “tennis” (more properly, “lawn tennis”) is derived?
ChatGPT doesn’t even begin to have anything within its model relevant to answering any of these questions.
In the novel The A.B.C. Murders, Hercule Poirot asks an interesting question about a murder victim. There are two versions of it I’m aware of; one is the version that Agatha Christie wrote and the other the version in the ITV version starring David Suchet. I’m going to quote both versions because they’re interesting to compare.
First, the original:
“Pas ga. I wondered — if she were pretty?”
“As to that I’ve no information ,” said Inspector Crome with a hint of withdrawal. His manner said: “Really — these foreigners! All the same!”
A final look of amusement came into Poirot’s eyes.
“It does not seem to you important, that? Yet, pour une femme, it is of the first importance. Often it decides her destiny!”
Then, the ITV version (which replaced Inspector Crome with Chief Inspector Japp):
Poirot: Was she pretty?
Inspector Japp: There he goes again.
Poirot: That does not seem to be important? Mais pour un femme, it is of the first importance. It often decides her destiny.
Curiously, that’s rather different than how I remembered it, and much closer to the book. I remembered the exchange in the ITV version as something like:
Poirot: Was she pretty?
Japp: What does that matter?
Poirot: Poor girl, it mattered a great deal to her. It decided the whole course of her life.
It is interesting to me that I misremembered the ITV version so much, though to be fair to me I like my version better. Since you, dear reader, are not me, I presume that Agatha Christie’s version is the most interesting, here, and quite rightly so.
A great deal of detective fiction might be written by a male or female author, but occasionally one comes across a passage that seems like it could only have been written by one or the other. This is one such passage. I can only imagine a woman writing this. It’s not that only a woman would know it; we all know that physical beauty affects the lives of both sexes. Perhaps the best way I can describe what I mean is another example of this, from the Hamish MacBeth story Death of a Gossip.
I had mentioned to a female friend of mine that the story was very markedly written by a woman and she jokingly asked, “what, did it have no descriptions of women’s breasts?”
“Oh, no, it’s got plenty of descriptions of women’s breasts,” I replied. “Just never in admiration.”
In the exchange above, whether the woman was pretty was quite relevant to the detection. She was strangled with her own belt and it takes an unusual kind of man to charm the belt off of a pretty woman for the simple reason that she will be used to getting attention from men and so to charm her he will need to be above average. Or as Poirot puts it:
Betty Barnard was a flirt. She liked attention from a personable male. Therefore A.B.C., to persuade her to come out with him, must have had a certain amount of attraction — of le sex appeal! He must be able, as you English say, to ‘get off.’ He must be capable of the click!
Since it is directly relevant to the solving of the murder, any author might have thought of it or mentioned it. There is just something about how it was mentioned which seems distinctly feminine to me, even though it is put in the mouth of a male character. It’s hard to articulate what, since it’s subtle.
I think it’s the sympathy involved.
Males are tempted to treat beautiful women better than plain women and so it is a mark of virtue to a male to treat plain women as well as he treats beautiful women. A male recognizes the temptation otherwise, but (a virtuous one) regrets it as the effect of a fallen world. Since women are affected by this temptation but are not actually tempted by it, their primary concern is on its effects, not on avoiding it. When Poirot says that whether a woman is pretty many decide her whole destiny, it only speaks to concern with the effect.
However that goes, it is a relatively subtle point that Agatha Christie handled very deftly. Her writing tended toward the plain side, but her psychology and her plots were masterful. This may well be why she is one of the best selling authors of all time; the plain style of her writing makes it extremely accessible, while at the same time the brilliance of the plot is easy to see.
Last Sunday’s reading at Mass was from the Gospel of John, and was the story about Jesus giving sight to the man born blind. Towards the end of the story, after the man born blind is questioned by the pharisees, he runs into Jesus, who asks the man whether he believes in the Son of Man. The man born blind asks a very interesting question: “Who is he, Sir, that I may believe in him?” (emphasis mine.)
It is interesting to contrast this with Pontius Pilate when Jesus said, “For this I was born and for this I came into the world: to testify to the truth. And those who are of the truth hear my voice.” Pilate’s response was, “Truth? What is truth?”
Jesus answered only one of these men, though they were, in a sense, asking the same question.
It’s interesting to contemplate why.
They were asking essentially the same question, but for opposite reasons. The man born blind was asking so that he may believe. A man cannot believe in something he does not know; faith is not the opposite of knowledge, but actually impossible without knowledge. The man who was born blind was willing to have faith, but he did not yet have the knowledge which would let him have faith, so he asked for it.
Pontius Pilate asked for knowledge in order to avoid believing in it. His question was not the seeking of truth but rather the denial of the possibility of attaining truth.
Despite what internet trolls will tell you, questions are not neutral things. We do not encounter questions floating in a vacuum. Questions always come from questioners, and questioners always have a goal in asking their questions.
As G.K. Chesterton said in Orthodoxy, motives matter:
But there is an anti-patriot who honestly angers honest men, and the explanation of him is, I think, what I have suggested: he is the uncandid candid friend; the man who says, “I am sorry to say we are ruined,” and is not sorry at all. And he may be said, without rhetoric, to be a traitor; for he is using that ugly knowledge which was allowed him to strengthen the army, to discourage people from joining it. Because he is allowed to be pessimistic as a military adviser he is being pessimistic as a recruiting sergeant. Just in the same way the pessimist (who is the cosmic anti-patriot) uses the freedom that life allows to her counsellors to lure away the people from her flag. Granted that he states only facts, it is still essential to know what are his emotions, what is his motive. It may be that twelve hundred men in Tottenham are down with smallpox; but we want to know whether this is stated by some great philosopher who wants to curse the gods, or only by some common clergyman who wants to help the men.
Back during the pandemic I did a number of posts looking at all-cause mortality in the USA. As a reminder, all-cause mortality is worth looking at because of the clarity of its definition. To give an example, if somebody has COPD and gets COVID-19 and dies, but probably wouldn’t have died if they only had one (then; COPD is eventually fatal), do you classify that as a COVID-19 death or a COPD death? Or as both? Different medical systems will reasonably differ on this question. (Then there are far less reasonable diagnostic criteria, like recording all deaths where a person had COVID-19 regardless of the cause of death.) This stuff can vary from hospital to hospital and state to state.
All-cause mortality data gets around these problems because, while it can be hard to agree on why a person died, it’s easy to agree on whether they died. Eventually. There is still the problem that it can take months for a death to actually be reported to the CDC. So much so that the CDC doesn’t even bother publishing all-cause mortality data for the most recently two weeks, and there’s very little point in looking at the last 3-6 weeks of data that they do publish. (They have algorithms that try to predict how many deaths will be reported eventually based on the data that has been reported so far, but it has a tendency to under-count what eventually gets reported.)
As I said, I put up several posts looking at this during the pandemic, and I recently became curious to look at it again now that the pandemic is in retrospect. So, here’s the data from the CDC as of February 20, 2023:
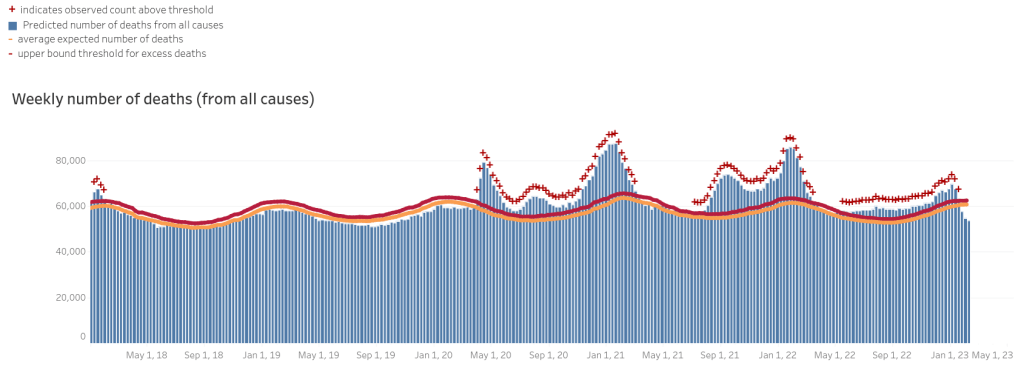
Let’s look at it a bit closer. To make the time frame of the data a little easier to follow, I’ve marked the approximate location of January 1 with yellow lines and the approximate location of July 1 with green lines:
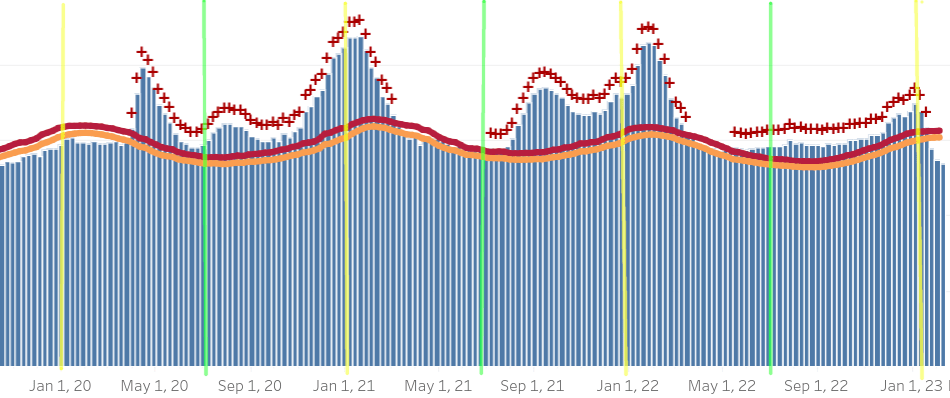
If you’re curious, the Pfizer vaccine received emergency use authorization in December of 2020. The more infectious Delta variant of SARS-CoV-2 was named in March of 2021. The Delta variant had mutations in the spike protein which is how the virus enters cells as well as the thing that the vaccine gives the immune system to detect. This simultaneously made it better at entering cells, and also reduced the efficacy of the immune response acquired through vaccination or infection with the original variant.
Because I sometimes would look at Sweden’s data, here’s their COVID-19 deaths/day as reported by the Swedish government:

This data is in no way directly comparable to the all-cause mortality data above, but it is none-the-less interesting to note how, with the exception of Summer 2020, the spikes like up pretty well. It is widely theorized that the US’s summer spikes correspond to air-conditioning season in the southern united states, when people stay indoors during waking hours. To the best of my knowledge, Swedish summers are far more mild than are the summers in the American south, so one would expect them to be absent.
That hypothesis brings up an interesting question looking at the USA data, though: why was there no summer spike in 2021? There was a spike in deaths in the fall of 2021, not the summer. One explanation is that COVID-19 deaths started taking longer since the onset of infection to kill people (or at least to contribute to their death). If that is the case we would expect all subsequent spikes in deaths to also come later and, indeed, they do. The winter spike in deaths (in early 2022) also came later than the spike in the winter of 2020/ 2021.
If that is the case, why should it be? One hypothesis which covers these facts—though is in no way certain—is that later mutations of SARS-CoV-2 took much longer to kill people than the original ones did. Another hypothesis which would explain the delay is that the most vulnerable people were killed off in the first waves, and everyone who is left are less susceptible. (Though they are less susceptible, it can still contribute to their deaths when they are weakened by other diseases.) These are just two hypotheses; the truth could involve some version of either, both, or neither.
Of course, another explanation which covers this data is that the response to the increases in prevalence of SARS-CoV-2, or very technically, the response to increasing numbers of positive SARS-CoV-2 tests, was responsible for the increase in deaths. This will, of course, vary among the states as they had very different responses to COVID; some states like California were known for draconian measures, while other states imposed very few restrictions, and many were inbetween. It is reasonable to suppose that the extra stress of lockdowns, closure of businesses, etc. would have some negative effect. There are no actions without consequences and it would be absurd to suppose that drastic actions like the ones taken in response to COVID-19 are free.
For reasons relating to other data I’ve looked into but don’t have time to get into here, I am skeptical that this explains all of the increase in mortality over the years before COVID, but I haven’t seen any data to conclusively rule that possibility out. I am also a bit resistant to this explanation because it would be too convenient; I think that the responses to COVID-19, after the first few months, were wildly overblown and a massive overreach of government power. Lockdowns could be justified in the face of a pandemic of the magnitude of the Black Death—something that could kill off a third of the population in a short time. During the very early rapid spread of SARS-CoV-2 there were reasons to believe that SARS-CoV-2 was an escaped bio-weapon that could have been that kind of threat—the kind of threat which could potentially justify temporarily suspending all of the normal rules of society. After a few months it was obvious that SARS-CoV-2, escaped bio-weapon or not, was in no way another Black Death. Since I think that what ensued as an unjustified massive overreaction, it would be very convenient if SARS-CoV-2 was barely worse than a normal flu and most of the bad consequences of it were actually due to what I consider to be an overreaction.
I like to be careful of convenient conclusions, especially when conclusive evidence is intrinsically hard to come by.
Whatever the cause and whatever exactly happened, it does seem very clear that it’s over. A few people still wear masks, but few enough that they might all be immuno-compromised people for whom trying to filter the air that they breathe in public places makes sense anyway. We still have some lingering excess mortality, though only slightly. It was never all that high—this is more clear when you look on a multi-year timescale rather than zooming in—and it is very possible that the last few years were a perfect example of Alexander Pope’s line, “a little learning is a dangerous thing.”
We had tests to detect the SARS-CoV-2 virus, but we didn’t know how it spread, how bad it was, or how bad it would be. Thirty years before, without the tests to detect the virus, the entire experience might have been radically different. The absolute worst weeks had increases in mortality of about 40%, but a 40% increase in a small number is still small. Throughout everything, there were only a few cases of hospitals becoming so over-full that they had to send patients elsewhere and there were no (or at least statistically no) instances of people dying because of a lack of treatment because the hospitals were full. Without the PCR tests that could detect the virus without symptoms (or with symptoms that could be a cold or the flu), and thus allow us to map out its spread, we might not have done much more than think that there was a nasty flu for a few years.
I recently came across this interesting video on a quasi-scandal involving Samsung smartphone cameras taking better pictures of the moon than the physical camera elements actually allows:
The video brings up an interesting question about what the pictures that smartphones take actually are. In the video Marques proposes that the images that the smartphone generates are something along the lines of an image which is what the smartphone “thinks” you want the slice of reality you were trying to capture to look like.
It’s no secret that smartphones these days do massive amounts of processing on the photos that they take and that this goes way beyond removing noise and compensating for camera shake; for years now they’ve been actively recognizing the subject in front of them and adjusting focus, faking bokeh (the way in which subjects behind the focal plane are blurred), punching up colors, adjusting contrast in only some parts of the picture, etc. etc. etc.
There is a problem with this when it comes to taking pictures of the moon, though, because there is only one moon, we only ever see one part of it because it’s tidally locked to the earth, and we’re so far away from it that there is effectively only one angle to take the pictures from. In short, except for haze in the atmosphere or objects in front, there’s only one picture you can take of the moon.
Using AI to improve pictures of the moon is thus not easily distinguished from just replacing your picture with a better picture of the moon. It is different; the approach Samsung uses preserves whatever color in the moon you see due to haze in the atmosphere (a honey moon, a red moon, etc) and won’t override a cloud or bird in front of the moon when you take the picture. But if you’re not capturing weird lighting or something in front of the moon, a cleared-up version of your picture of the moon isn’t really different from just using a better picture instead.
Smartphones have been clearing up the pictures that they take for a long time now, and for the most part people don’t really object. (Every now and then when posting pictures of my superdwarf reticulated python to Instagram I have to note that the camera punched up the color, though it’s not a big deal because it’s what he looks like outdoors in sunlight, so it’s only a slight inaccuracy.)
It’s just weird that there happens to be a subject where you can only take one picture and so the AI image enhancement doesn’t need your original photo to present a clearer version of the photo you took. From what we can tell it does use your photo and doesn’t improve every photo of the moon to a pixel-perfect photo of the moon, but in some sense that’s just an implementation detail and imperfect photo enhancement, respectively.
Of course, the same thing that makes this a problem makes it purely academic; there’s no important reason to take photos of the moon because at best they look exactly like photos you can easily look up. And if you’re doing it for fun, you’re going to use a real camera not a smartphone camera.
It is an interesting academic problem, though.
During the golden age of mysteries, a great many of the stories were (of necessity) set against the backdrop of drastic changes in society. These changes often provided motives as well as opportunities for the murders. Motives would often be the desire for money to be used on something other than maintaining the vestiges of an old way of life that the new generation is not interested in. The opportunity provided is often along the lines of a large house with few people in them. It’s that latter part that really interests me at the moment.
Large, derelict houses make great settings for mysteries, and I think that this is especially the case in mysteries for children. Scooby Doo was very frequently set in large houses with few people in them, isolated from their neighbors by large plots of land. These are things that most easily happen when societal changes make things that had been popular, or at least populous, less so. When things get abandoned, or even just partially abandoned, there become the remnants of things that people used to do without there being the people around to explain what they were. This makes such a setting is intrinsically mysterious. Whatever crimes a villain is currently committing, there are many things that need an explanation but without the people present who know what they are to give the explanation. Figuring them out, then figuring out which of these is innocuous and which nefarious can provide a wealth of things for the detective to use his intellect on.
This scope for investigation provided by the former scene of a bustling community now in some state of abandonment can be amplified by the intertwining of the current mystery with previous events. This can take the form of treasure which can be discovered or inherited, but it can also take the form of the deeds or misdeeds of the past influencing revenge in the present. It can take the form of both, separately or intertwining.
So how do we make use of this in contemporary murder mysteries? (I mean, murder mysteries set in at least approximately the time of their writing, as opposed to historical murder mysteries.) Many of the social changes which formed fertile ground for Golden Age murder mysteries are, in the twenty first century, over. The remnants of the medieval system are now pretty much entirely gone in England and, to the degree that the southern plantations and robber barons of the United States formed some counterpart, they’re gone too. We still have billionaires, of course, but for a variety of reasons they have fewer servants. (Part of this is technology, part of it is a more efficient economic system where things like cleaning and landscaping are more efficiently done by companies with specialized equipment who service multiple clients.) Even where a billionaire has something potentially interesting like a hundred million dollar yacht, the things are all new. An American billionaire’s household was assembled fairly recently. The odds are pretty good that his house was built fairly recently. The odds of a billionaire’s parents being billionaires is… not high. There are wealthy families, of course, and some of them even have history. I think these can work for this kind of murder mystery—the wealth of wealthy families tends to substantially diminish with each generation. There are exceptions, of course, but children are so frequently different from their parents that it’s rare for the grandchildren of someone who built up a fortune to have even a quarter of their grandfather’s talent for making money, and even less of his being in the right place at the right time to take advantage of that talent.
I suspect that there is more, in the contemporary United States, that can be made of institutions falling on hard times. That happens in all ages, but especially in our contemporary industrial times. Businesses, schools, hospitals, and more go out of business all the time; plenty come close to it or shrink before they’re bought out by competitors. Not every business would be ripe for this kind of setting, but I suspect a lot would. If one couples this with the advisability of Fun Settings for a Murder Mystery, there’s a lot of fertile ground, here.

You must be logged in to post a comment.